作者介绍:皮吉斯,热爱R语言,知乎号:皮吉斯
已授权转载
本次的分析数据来自kaggle数据竞赛平台的 “give me some credit” 竞赛项目。任务是提高模型精度AUC。
本次分析用到了多种算法,分别有:逻辑回归,cart决策树,神经网络,xgboost,随机森林。通过多种模型相互对比,最终根据auc选出最好的模型。
分析步骤:
- 导入数据
- 数据清洗及准备
- 模型建立
- 模型评估
- 多模型对比
导入数据
1 | cs_training <- read.csv("cs_training.csv") |
导入数据,并对列名重命名,方便分析。
通过summary了解数据的整体情况,可以看到monthliincome和x7变量有缺失值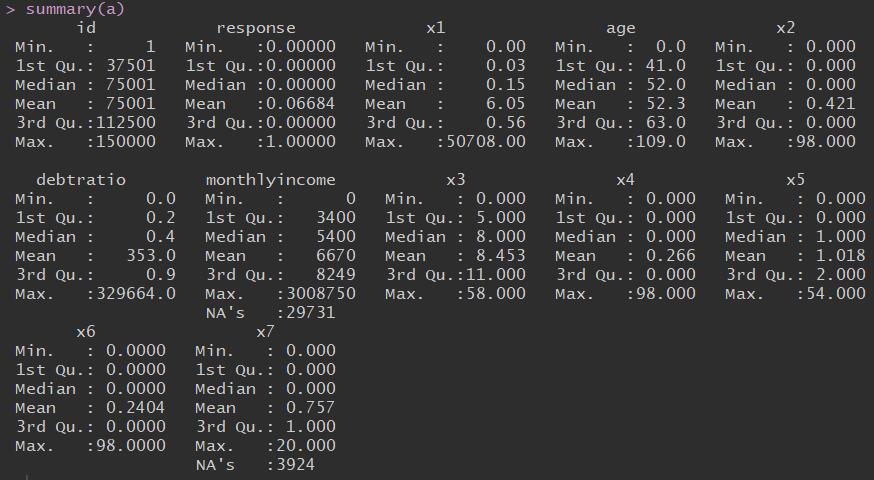
数据清洗
1 | #age变量 |
| var | mean | median | 0 | 0.01 | 0.1 | 0.25 | 0.5 | 0.75 | 0.9 | 0.99 | 1 | max | missing |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| age | 52.2952066666667 | 52 | 0 | 24 | 33 | 41 | 52 | 63 | 72 | 87 | 109 | 109 | 0 |
这样可以看到各个变量的数据分布情况1
2# 查看异常值
boxplot(age~response,data = a,horizontal = T ,frame = F , col = "lightgray",main = "Distribution")
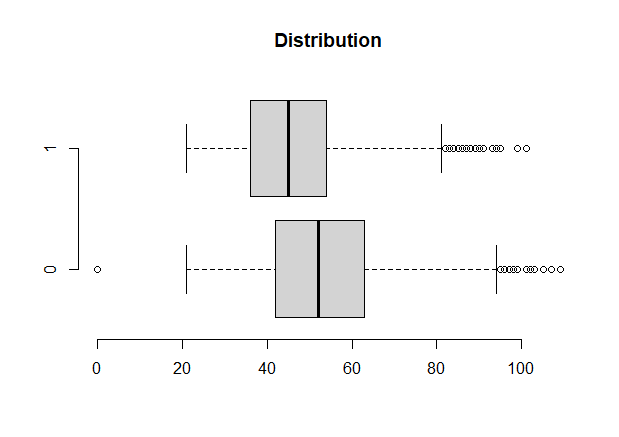
上图可以看到,数据存在异常值。
处理异常值:通常采用盖帽法,即用数据分布在1%的数据覆盖在1%以下的数据,用在99%的数据覆盖99%以上的数据。1
2
3
4
5
6
7
8
9
10
11
12block<-function(x,lower=T,upper=T){
if(lower){
q1<-quantile(x,0.01)
x[x<=q1]<-q1
}
if(upper){
q99<-quantile(x,0.99)
x[x>q99]<-q99
}
return(x)
}
boxplot(age~response,data = a,horizontal = T ,frame = F , col = "lightgray",main = "Distribution")
经过处理,异常值大量减少1
2
3
4
5
6
7
8
9
10# x1
xa1<-a$x1
var_x1<-c(var='xa1',
mean=mean(xa1,na.rm = T),
median=median(xa1,na.rm = T),
quantile(xa1,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(xa1,na.rm = T),
miss=sum(is.na(xa1)) )
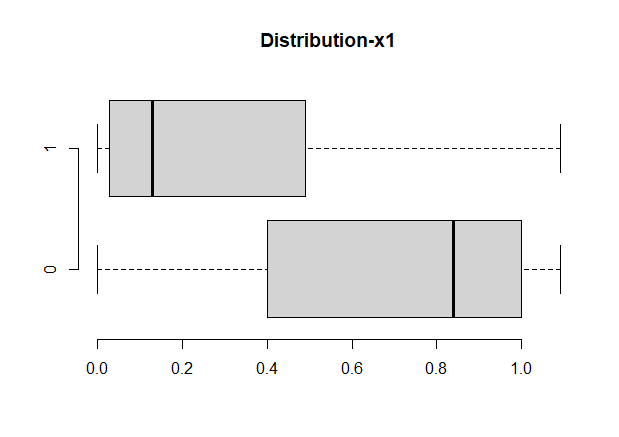
boxplot(x1~response,data=a,horizontal=T, frame=F, col="lightgray",main="Distribution-x1")
#对X1变量进行处理
a$x1<-block(a$x1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# x2
a$x2
summary(a$x2)
xa2<-a$x2
var_x2<-c(var='xa2',
mean=mean(xa2,na.rm = T),
median=median(xa2,na.rm = T),
quantile(xa2,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(xa2,na.rm = T),
miss=sum(is.na(xa2)) )
boxplot(x2~response,data=a,horizontal=T, frame=F, col="lightgray",main="Distribution")
# 对x2变量进行处理
a$x2<-block(a$x2)
a$x1<-round(a$x1,2)
# debtratio
summary(a$debtratio)
ratio<-a$debtratio
var_ratio<-c(var='debtratio',
mean=mean(ratio,na.rm = T),
median=median(ratio,na.rm = T),
quantile(ratio,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(ratio,na.rm = T),
miss=sum(is.na(ratio)) )
hist(a$debtratio)
# 因为debtratio是百分比,对异常值的处理要结合实际
a$debtratio<-ifelse(a$debtratio>1,1,a$debtratio)
# monthlyincome
income<-a$monthlyincome
var_income<-c(var='income',
mean=mean(income,na.rm = T),
median=median(income,na.rm = T),
quantile(income,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T),
max=max(income,na.rm = T),
miss=sum(is.na(income)) )
hist(income)
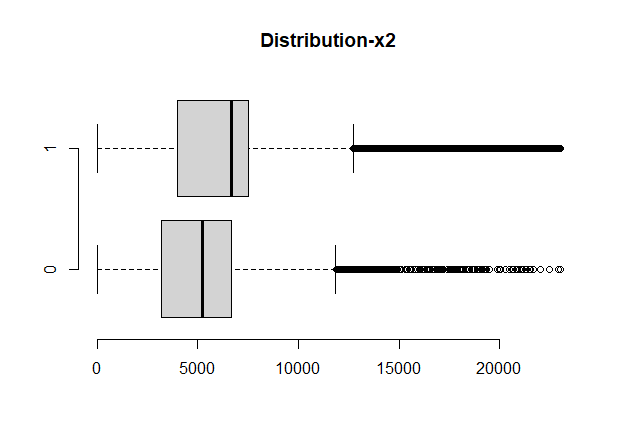
boxplot(monthlyincome~response,data=a,horizontal=T, frame=F, col="lightgray",main="Distribution-x2")
# 对缺失值处理
a$monthlyincome<-ifelse(is.na(a$monthlyincome)==T,6670.2,a$monthlyincome)
# 对异常值处理
a$monthlyincome<-block(a$monthlyincome)
1
2
3
4
5
6
7
8
9
10# x3
summary(a$x3)
x3<-a$x3
var_x3<-c(var='x3',mean=mean(x3,na.rm = T),
median=median(x3,na.rm = T),
quantile(x3,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(x3,na.rm = T),
miss=sum(is.na(x3)) )
names(a)
# 对x3进行处理
a$x3<-block(a$x3)
1 | # x4-延迟90天的次数 |
1 | # x5-贷款额度 |
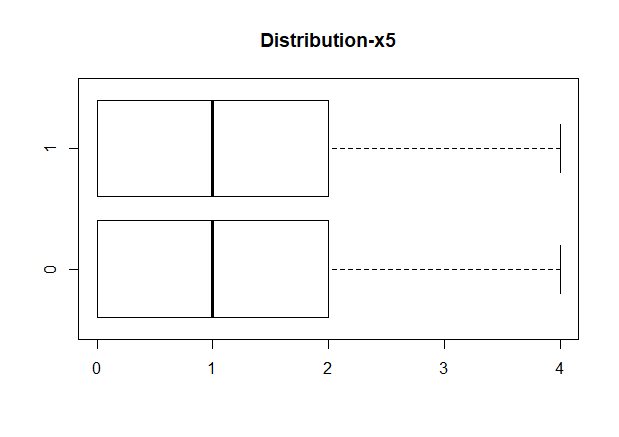
1
2
3
4
5
6
7
8
9# x6
summary(a$x6)
x6<-a$x6
var_x6<-c(var='x6',mean=mean(x6,na.rm = T),
median=median(x6,na.rm = T),
quantile(x6,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(x6,na.rm = T),
miss=sum(is.na(x6)) )
# 对x6进行盖帽法
a$x6<-block(a$x6)
1 | # x7 |
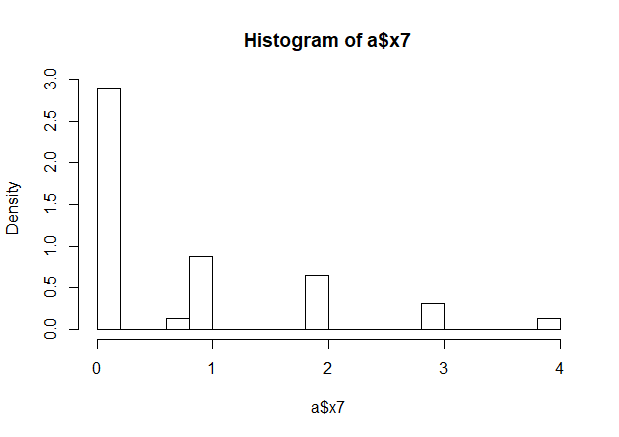
1
2
3#response变量
# 为了方便理解,将1作为违约,0表示不违约
a$response<-as.numeric(!as.logical(a$response))
建模
数据分组
1 | table(a$response) |
| 0 | 1 |
| 10026 | 139974 |
数据正负比例不平衡,我们要对数据进行smote处理,smote算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
1 | library(lattice) |
1 | # 接下来进行分组 |
table(train$response)
| 0 | 1 |
| 21213 | 27914 |
table(test$response)
| 0 | 1 |
| 8865 | 12190 |
逻辑回归
建立模型
1 | glm_model <- glm(response~. , data = train , family = binomial()) |
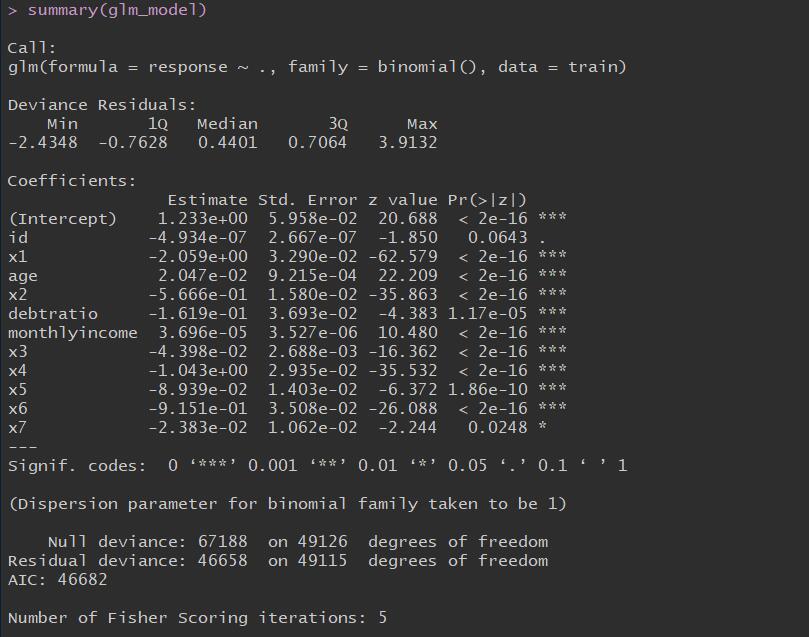
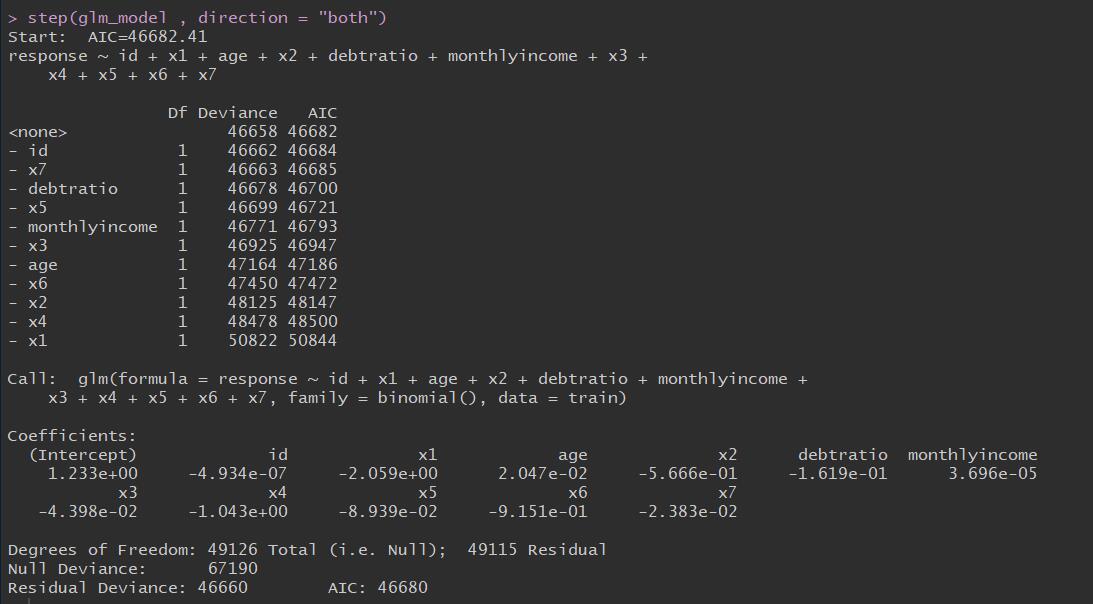
使用逐步法剔除变量
1 | step(glm_model , direction = "both") |
VIF多重共线性检验
1 | library(carData) |

预测
1 | train_pred <- predict(glm_model , newdata = train , type = "response") |
模型评估(auc=0.842466)
1 | library(gplots) |
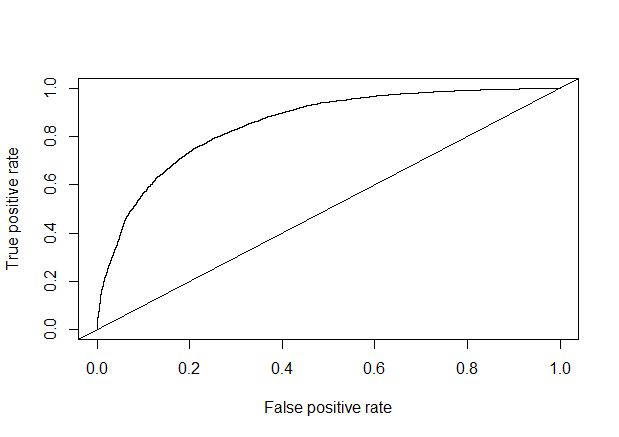
cart决策树模型
模型建立
1 | library(rpart) |
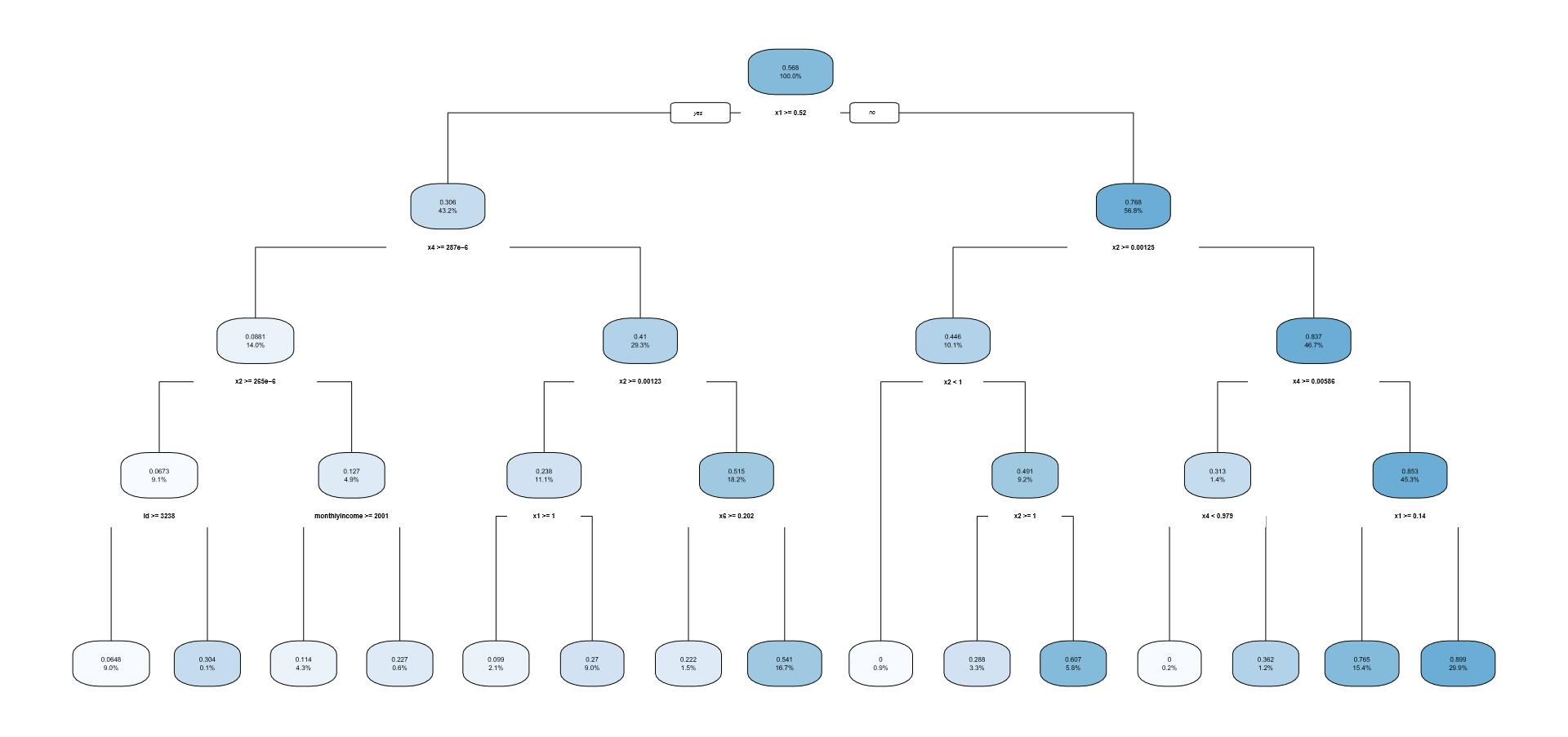
预测
1 | test_pred <- predict(cart_model , newdata = test) |
模型评估(auc=0.3670627)
1 | test_prob <- prediction(test_pred, test$response) |
nnet包的单隐层BP网络
对数据进行标准化
1 | #对数据进行标准化 |
模型建立
1 | library(nnet) |
预测并将概率调整为0和1
1 | test_pred<-predict(train_nnet, test) |
test_pred
| 0 | 1 |
| 14523 | 6532 |
计算准确率
1 | test_pred_rate<-sum(test_pred==test$response)/length(test$response) |
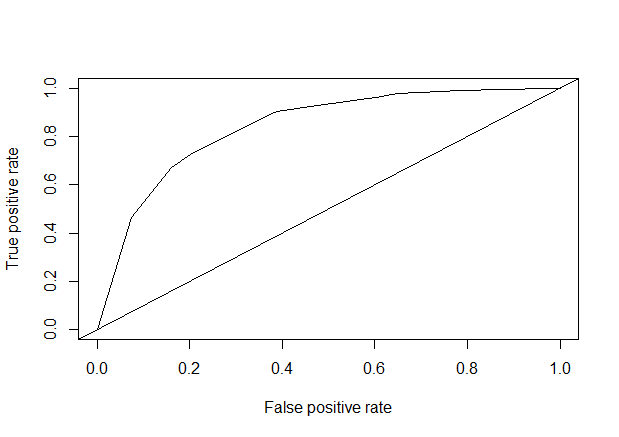
模型评估(auc=0.7848754)
1 | library(gplots) |
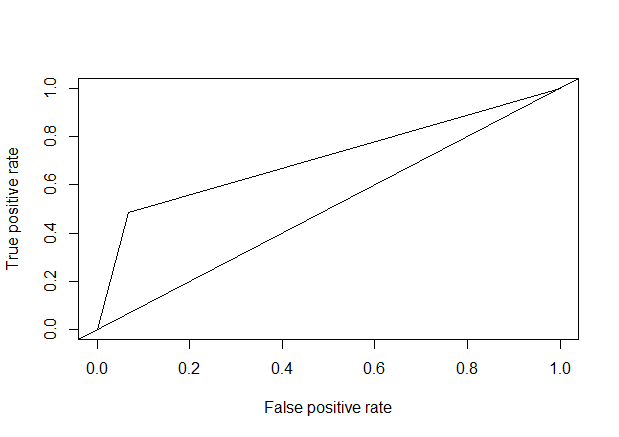
模型调参
1 | ##输入数据的预测变量必须是二分类的。且所有变量只包含模型输入输出变量。 |
建模2.0
1 | #调参后的模型 #size =11 , decay = 0.0013 , maxit = 200 |
模型评估(auc = 0.7923195)
1 | # 预测为0,1 |
xgboost算法
模型建立
1 | library(xgboost) |
预测
1 | test_prob <- predict(xgb_model , data.matrix(test[,-1])) |
模型评估(auc = 0.860617)
1 | test_pred <- prediction(test_prob , test$response) |
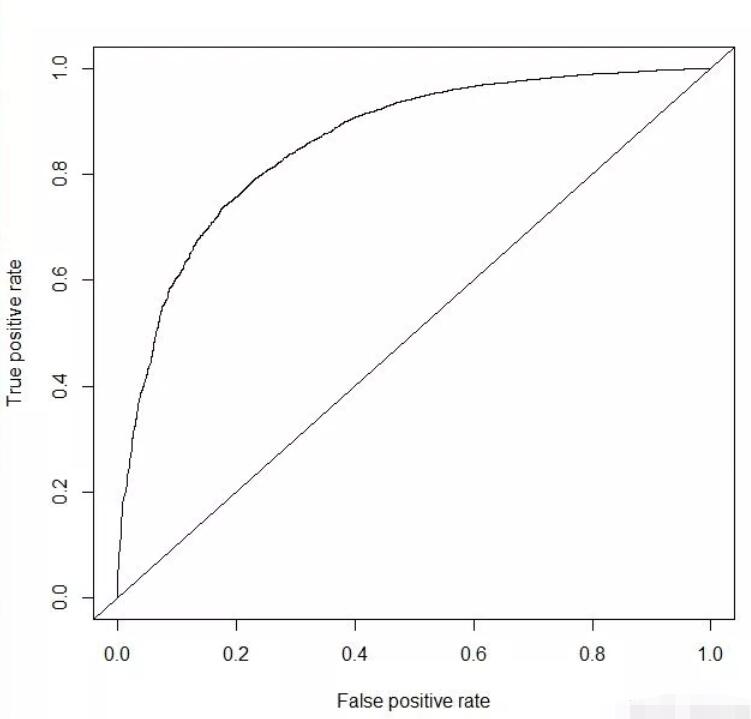
随机森林
模型建立
1 | library(randomForest) |
模型预测
1 | test_prob <- predict(random_model , test , type= "response") |
模型评估(auc = 0.8531173)
1 | test_pred <- prediction(test_prob , test$response) |
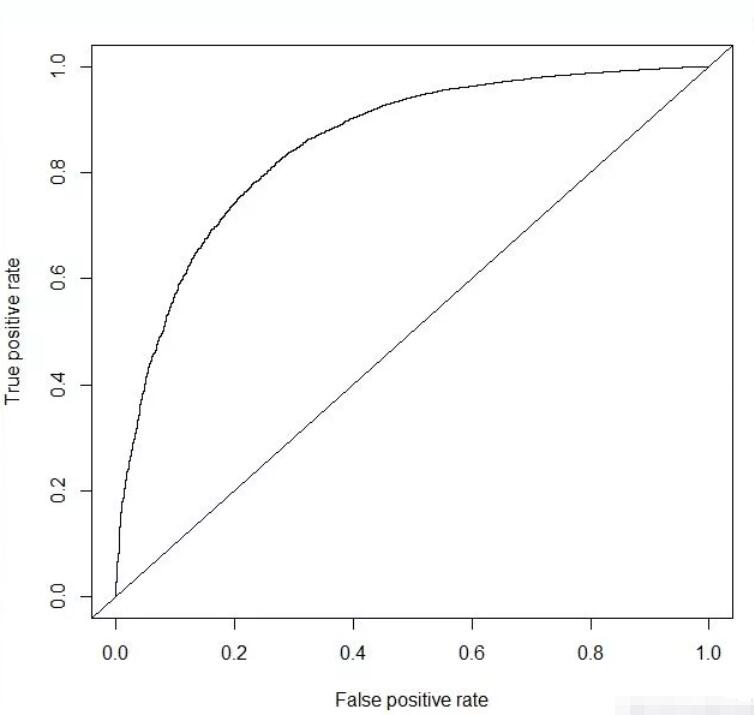
综上,通过多种模型对比可以看到xgboost算法的模型精确度是最高的达到0.860617。